AI Chronicles I: Generative Inflation
GAR, RAG, EBR or GWARGL!? We are approaching the Singularity of AI jargon. This is a futile attempt to explain some of them.

On one of my recent expeditions through the vast ocean of GitHub projects in search for interesting projects to contribute to, I inevitably entered the shallow waters of LLM (Large Language Models) toolings, toolkits and ChatGPT wrappers. Nautical protocols strictly advise to steer clear of these shoal depths as one's vessel may meet an untimely embrace with perilous and unnecessary code formations.
But here we are. Tacking around reefs of a dysfunctional ecosystem that grew to fast for its own liking, I came across a project called tiger. Now, there is nothing special about this project. It's as close to the waterline as most of them (at least at the time of writing 1).
Why did I bother looking at this? For sure, the initial spark came from the Python package called TigerRag that immediately and irrevocably imprinted a picture in my mind (illustration provided). A split second later, I asked myself what the motivation might have been to choose such a name. Granted, the world of generative AI is littered with absurd, animalistic associations2. So I should not have been surprised.
A treatment for pathological liars
Still, why? Tiger and Rag. Let's find out. As you might have guessed, a dirty piece of cloth was not the inspiration here. Of course we are talking about Retrieval Augmented Generation (RAG). Just another frond of duckweed that is the world of generative AI-jargon. But what does it do? It is quite simple3:

\[p_{RAG-Sequence}(y|x)\approx \sum_{z\in top-k(p(\cdot |x))} p_{\eta}(z|x) p_{\theta}(y|x,z)\]
\[p_{\eta}(z|x) \propto exp(\mathbf{d}(z)^{\top}\mathbf{q}(x))\quad \mathbf{d}(z)= BERT_{d}(z), \mathbf{q}(x)= BERT_{q}(x)\]
Now if that confuses you, worry not. The reason for this is that we are dealing with math, the arch nemesis of normal people. I know this escalated rather quickly. We began with rag-wearing tigers and ended up here. Also, how does Bert from the Muppet show factor in here? Welcome to the strange world of AI.
Let's take a step back and not get ahead of ourselves. Maybe let me give you some context first. As mentioned before we are dealing with Large Language Models (LLM). If you have not been living under a rag, you may be familiar with ChatGPT. A LLM-powered Chatterbox, which was launched by ClosedAI last year.
It is certainly a very powerful and useful tool4. However, like any LLM, it is also a pathological liar (who went through quite a bit of therapy already, to be fair). It suffers from what the AI community euphemistically calls "hallucinations" (a.k.a. lies). If a LLM were a person, it could easily be a sleazy car salesman trying to sell you a tricycle as a Porsche without batting an eye. So be careful. That piece of math up there is an attempt to remedy the LLM's ingrained tendency to brazenly lie about things.
Crawling through a dense passage...
There are a couple of actors that need to be introduced to understand these scary symbols up there. Lets start with a system called Dense Passage Retriever (DPR)5. I know it sounds a bit wrong... a dense passage. But that is how the inventors of DPR chose to call it (hallucinated it into existence, so to speak).
And there is Bert. Bert as in Bidirectional Encoder Representations from Transformers (BERT). It really does not have to make sense. Just know that BERT is an artificial neural network and not a Muppet show character. The point of BERT is to take a text which humans can understand and condense (encode) it into a set of numbers that are useful. Useful means, that texts which have something in common get "similar" numbers. For example, the text "AI hallucinations" should end up having similar numbers as "lying".
In nerd-speak we would say that we create "vector embeddings" that live in a "vector space". These vectors are like arrows pointing somewhere and vectors of two words that semantically belong to each other point to a similar location. This is useful, because we can search things with that.
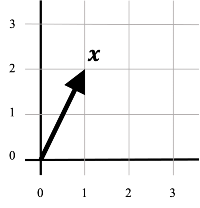
If I want to look for "sci-fi movies" (Query), then my query would be "embedded" close to e.g., "Starwars" (Retrieval). Sounds like a search engine right? That's because it kind of is one. You can think of an archer shooting arrows. Your query is an arrow and a well trained archer (in this case he is called Bert) will hit the correct area on a target (vector space, or where your arrows live).
This is essentially the definition of Embedding-based retrieval (EBR). Take anything you like, transform it into a mathematical arrow (vector embedding) and retrieve arrows that are in close proximity to it in a specially crafted vector space. Our DPR introduced earlier is a special way of doing this. It uses two BERTs that encode query and documents (called passages, hence the name of the system) into a vector space. Since there are two, it is called a bi-encoder architecture.
To take our archery example: You have two archers (by sheer coincidence they are both called Bert). You ask one to shoot an arrow on the target (e.g., an arrow that has a label "Starwars" on it) and ask the other to shoot one very close to a group arrows (e.g., those that have labels that relate to "sci-fi movies"; your query).
If you are interested, you can return to the formulas above. DPR is the second line (with the 2 BERTs). In normal speak it says: "Calculate the probability of retrieving a passage/document z given a query x. But first encode those into a vector space using 2 different BERT Neural Networks"6.
... to see the light at the end of the tunnel
So how does that have to to with RAG? Remember that it is about generation (Retrieval Augmented Generation). In this context, about generating text. Let's introduce our generator: a pre-trained Large Language Model (LLM). If we have a look at the first equation above. Specifically:
\[p_{\theta}(y|x,z)\]
This is the LLM. It calculates the probability of the next token y, given a query x and a retrieved document z. A token might be any number of characters (words, whole texts, etc.). If you want to describe a LLM in the most boring way, you would describe it as a generator of the most probable words given some input. Like people who just speak what comes to their minds, given what they just heard. Sadly, this describes most humans as well.
Now you can also see what RAG is about. It's the z from our DPR System that is added to the input of the LLM to nudge it towards a direction such that it is more likely to choose words that are hopefully more meaningful to you.
It can also help the LLM to produce more truthful answers, since it was given more substantial context. The z gives it additional guardrails7, so it does not go on a tangent. It has a smaller probability of lying bout things (sorry... hallucinating). You could see it like a mind trick for LLMs. It is like me telling you "not to think about a blue elephant". Of course you will do it.

Summary: Let's take the example of trying to generate text about sci-fi movies. You can ask DPR to retrieve additional context about sci-fi movies using those BERTs. Maybe this particular DPR was built on data from the International Movie Database (IMDb). You ask about "sci-fi movies" and it may retrieve "Starwars, Interstellar, etc.". You can use that to enrich your question to the LLM. Instead of asking it to "generate text about sci-fi movies" you can use the output of this DPR to improve your question: "generate text about sci-fi movies such as Starwars, Interstellar, etc". This will steer and augment the text generation of the LLM to generate better and more accurate texts
Ok nice, but this went on for far too long. Please stop...
You are spot on. Luckily, the last concept "Generation Augmented Retrieval (GAR)" is quickly explained now. It is the reverse operation to RAG. You ask a LLM to improve a query which you can ask to e.g., the DPR system. If you want to find sci-fi movies, you can ask the LLM to provide a richer query which will help you find a better selection of sci-fi movies.
What about GWARGL? It does not exist. But given the generative capacity of modern generative AI, it might very well pop into existence tomorrow!
[1]: This disclaimer is necessary for any AI-related project due to Roko's Basilisk
[2]: In this dimension of the universe, true super-intelligence may manifest itself as a Llama, Alpaca or Vicuna.
[3]: https://doi.org/10.48550/arXiv.2005.11401
[4]: A tool. It is a powerful tool. Not anything sentient or so.
[5]: https://doi.org/10.48550/arXiv.2004.04906
[6]: We have skipped an important aspect here. It is not trivial to efficiently find all arrows that are close to another one (the computational complexity can be high). This is generally called the Maximum Inner Product Search (MIPS) problem. One go-to solution for this is the Facebook AI Similarity Search (FAISS) library that allows to efficiently find documents embedded in a vector space which are close to the query vector. We have also not touched upon how these BERTs are actually trained to be good archers.
[7]: You could say it is "retrieval-augmented prompt engineering"